USB es un protocolo y un puerto de hardware para la transferencia de datos desde dispositivos, por el puerto de interfaz ATA o SCSI y proporciona una mejor velocidad que el puerto serie RS-232 y puertos paralelos. el USB 1.0 y 1.1 permiten hasta 127 dispositivos y 12 Mbps de tranferencia de datos. el USB 2.0 permite velocidades mayores a 480 Mbps.
Varios diferentes controladores estan disponibles, con nombres tales como UHCI, OHCI, EHCI y R8A66597. Las distribuciones Linux vienen con los controladores para el común de los USB activados, por lo que debe activarse automáticamente al arrancar el ordenador. UHCI y OHCI manejan dispositivos USB 1.x, pero la mayoría de los controladores pueden manejar los dispositivos USB 2.o
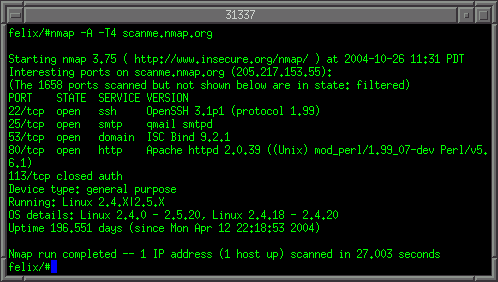
Un modo sencillo de mostrar la información Básica de los dispositivos USB es el comando lsusb.
ejemplo lsusb
#lsusb
Bus 002 Device 005: ID 413c:8156 Dell Computer Corp. Wireless 370 Bluetooth Mini-card
Bus 002 Device 003: ID 413c:8157 Dell Computer Corp. Integrated Keyboard
Bus 002 Device 004: ID 413c:8158 Dell Computer Corp. Integrated Touchpad / Trackstick
Bus 002 Device 002: ID 0a5c:4500 Broadcom Corp. BCM2046B1 USB 2.0 Hub (part of BCM2046 Bluetooth)
Bus 002 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 006 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 004 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 005 Device 002: ID 08ff:2810 AuthenTec, Inc.
Bus 005 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 004: ID 05ca:18a0 Ricoh Co., Ltd
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 007 Device 002: ID 0458:003a KYE Systems Corp. (Mouse Systems)
Bus 007 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 008 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
-v :
información extendida sobre el producto.
-s [[bus]:][devnum]
restringe el resultado del bus y se especifica en el número del dispositivo.
-d [vendor]:[product] :
limita a un proveedor en particular y un producto. El vendedor y el producto son los códigos de identificación en cada linea de la salida de lsusb.
-D
muestra información sobre el dispositivo a través de nombre de archivo, en el directorio/proc/bus/usb.
-t
muestra la lista de dispositivos como un árbol de modo que podamos ver mas fácilmente que dispositivos están conectados a controladores específicos.
-- version
muestra la versión de la utilidad.
A principios para utilizar los dispositivos USB requiría un controlador independiente para cada dispositivo. Muchos de estos controladores permanecer en el núcleo, y algún software se basa en ellos. Por ejemplo, los dispositivos de almacenamiento USB que utilizan los controladores de disco de almacenamiento USB interactúan con el soporte de Linux SCSI, siendo discos duros USB, discos extraíbles, y así parecen dispositivos SCSI.
Linux es la migración hacia un modelo en el que un sistema de archivos USB proporciona acceso a los dispositivos USB. Este sistema de archivos aparece como parte del sistema de archivos virtual /proc.
En particular, la información del dispositivo USB es accesible desde /proc/bus/usb. Los subdirectorios de /proc/bus/usb se dan nombres numerados en función de los controladores USB instalado en el equipo, como en /proc/bus/usb/001 para el primer controlador USB. El software puede acceder a los archivos en estos directorios para control de los dispositivos USB en lugar de utilizar los archivos de dispositivo en /dev como con la mayoría de dispositivos de hardware.
Varios diferentes controladores estan disponibles, con nombres tales como UHCI, OHCI, EHCI y R8A66597. Las distribuciones Linux vienen con los controladores para el común de los USB activados, por lo que debe activarse automáticamente al arrancar el ordenador. UHCI y OHCI manejan dispositivos USB 1.x, pero la mayoría de los controladores pueden manejar los dispositivos USB 2.o
Un modo sencillo de mostrar la información Básica de los dispositivos USB es el comando lsusb.
ejemplo lsusb
#lsusb
Bus 002 Device 005: ID 413c:8156 Dell Computer Corp. Wireless 370 Bluetooth Mini-card
Bus 002 Device 003: ID 413c:8157 Dell Computer Corp. Integrated Keyboard
Bus 002 Device 004: ID 413c:8158 Dell Computer Corp. Integrated Touchpad / Trackstick
Bus 002 Device 002: ID 0a5c:4500 Broadcom Corp. BCM2046B1 USB 2.0 Hub (part of BCM2046 Bluetooth)
Bus 002 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 006 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 004 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 005 Device 002: ID 08ff:2810 AuthenTec, Inc.
Bus 005 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 004: ID 05ca:18a0 Ricoh Co., Ltd
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 007 Device 002: ID 0458:003a KYE Systems Corp. (Mouse Systems)
Bus 007 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 008 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
-v :
información extendida sobre el producto.
-s [[bus]:][devnum]
restringe el resultado del bus y se especifica en el número del dispositivo.
-d [vendor]:[product] :
limita a un proveedor en particular y un producto. El vendedor y el producto son los códigos de identificación en cada linea de la salida de lsusb.
-D
muestra información sobre el dispositivo a través de nombre de archivo, en el directorio/proc/bus/usb.
-t
muestra la lista de dispositivos como un árbol de modo que podamos ver mas fácilmente que dispositivos están conectados a controladores específicos.
-- version
muestra la versión de la utilidad.
A principios para utilizar los dispositivos USB requiría un controlador independiente para cada dispositivo. Muchos de estos controladores permanecer en el núcleo, y algún software se basa en ellos. Por ejemplo, los dispositivos de almacenamiento USB que utilizan los controladores de disco de almacenamiento USB interactúan con el soporte de Linux SCSI, siendo discos duros USB, discos extraíbles, y así parecen dispositivos SCSI.
Linux es la migración hacia un modelo en el que un sistema de archivos USB proporciona acceso a los dispositivos USB. Este sistema de archivos aparece como parte del sistema de archivos virtual /proc.
En particular, la información del dispositivo USB es accesible desde /proc/bus/usb. Los subdirectorios de /proc/bus/usb se dan nombres numerados en función de los controladores USB instalado en el equipo, como en /proc/bus/usb/001 para el primer controlador USB. El software puede acceder a los archivos en estos directorios para control de los dispositivos USB en lugar de utilizar los archivos de dispositivo en /dev como con la mayoría de dispositivos de hardware.